Why I Built CheckApp — AI Content Quality Checker
Three articles that almost shipped
I spent most of 2025 ghostwriting. Marketing articles, SEO pieces, thought-leadership posts — the whole spread, for clients across fintech, wellness, and SaaS. By the middle of the year, AI had become the default first draft. And that's when I started seeing the cracks.
Three articles nearly shipped with problems that would have mattered.
One had a paragraph lifted almost verbatim from a Wikipedia entry on vitamin D. Three sentences. Enough for Copyscape to flag it at 33% similarity.
One stated a statistic confidently — "the average B2B buyer now engages with 13 pieces of content before purchasing" — that came from nowhere. No source. No paper. The number didn't exist.
One confidently promoted a supplement as "clinically proven to reduce inflammation in 72 hours." That's a straight FDA violation. The client would have been the one holding the bag.
Each of those articles looked fine on first read. Each one could have gone live.
I stopped trusting the workflow I had and started asking: what would a systematic quality gate look like? Not a better editor. A pipeline that checks the things editors miss.
So I built the tool I wanted.
What's actually broken with existing tools
Grammarly checks spelling and grammar. That's useful. It doesn't check whether your claims are true. It doesn't know that "13 pieces of content" is a made-up number. It's a spelling layer, not a quality gate.
ChatGPT as a fact-checker is worse than useless. Ask it to verify a claim and it'll answer confidently. Ask it to cite sources and it'll invent URLs that don't exist. LLMs are trained to produce plausible-sounding answers. Fact-checking is a retrieval problem. LLMs aren't good at retrieval — they're good at sounding right. Those are different things.
Copyscape alone catches plagiarism after you've already written the wrong thing. Useful for one check, one symptom. It doesn't tell you whether the content is factually defensible, legally safe, or tonally consistent with your brand.
Human review is the fallback everyone uses. Three reviewers signed off on all three of those articles. Human attention is finite, expensive, and does not scale when you're shipping 20 pieces a week across five clients.
Human review catches structure and flow. It doesn't catch a fabricated statistic that sounds credible.
The gap wasn't any of these tools individually. The gap was that nobody had composed them into a single pipeline that ran before publish.
What CheckApp does
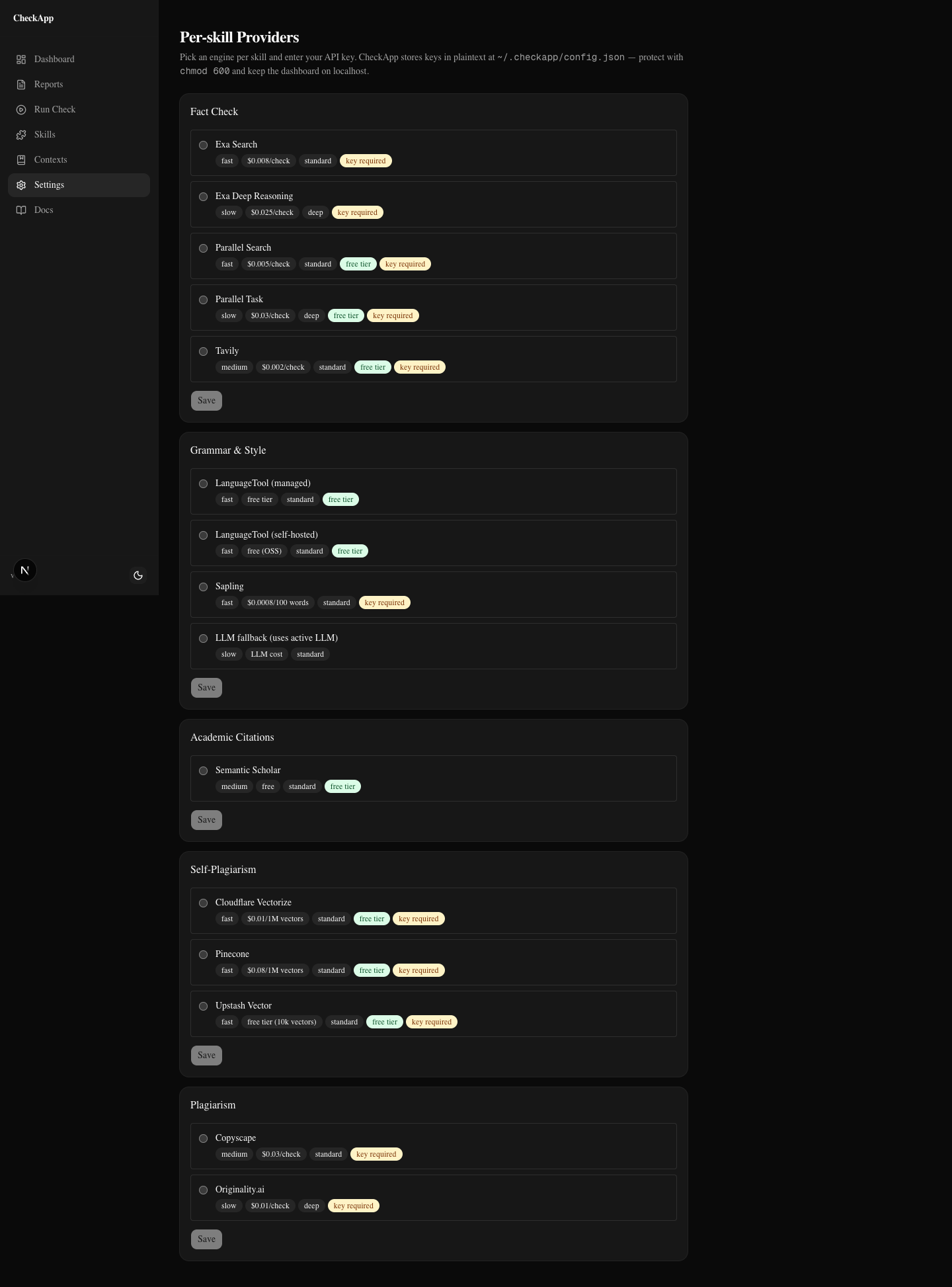
CheckApp is an AI content quality checker that runs 12 skills against any .md or .txt file, or a public Google Doc. It runs locally, takes under 30 seconds for a typical 800-word article, and costs $0.05–$0.25 per run depending on which providers you configure. Every skill lets you pick the provider that fits your budget — Exa Search or Parallel Task for fact-check, LanguageTool or Sapling for grammar, Claude or MiniMax for LLM skills. BYOK — you bring your own API keys and pay the providers directly. CheckApp takes zero margin.
v1.2.0 shipped. 338 tests passing. MCP server stable. Claude Code and Cursor users can call check_article as a native tool. That's not future work — that's today.
Here's the full pipeline, grouped by what it's actually checking.
Accuracy — did you get the facts right?
Fact-check extracts every factual claim in the article, queries your configured search provider for real sources, then asks the LLM whether those sources support the claim. It returns sources, citations, per-claim confidence scores, and a verdict. The sources are real URLs with relevance scores — not LLM memory. For medical, scientific, or financial claims, academic citations auto-merge via Semantic Scholar (free, no key required). Fact-check provider options are Exa Search ($0.007/claim), Exa Deep Reasoning ($0.025/claim, deeper retrieval), or Parallel Task (research-grade multi-hop reasoning).
Self-plagiarism detects overlap with your own past articles. Run checkapp index <dir> once against your archive and every future check will flag passages that too closely echo something you've already published. Supported backends: Cloudflare Vectorize, Pinecone, Upstash Vector (10k vectors free).
Quality — is it well-written?
Grammar & style uses LanguageTool as the primary layer (free managed tier, deterministic) and falls back to LLM for style issues LanguageTool misses. Findings come with offset-based rewrites — not broken find-and-replace. If you have 8 findings, your verdict is warn, not pass. Hebrew content uses Intl.Segmenter for correct sentence splitting.
SEO is fully offline — no API key required. Keyword density, readability score, heading structure. Free to run on every article.
Tone of voice compares the article against a brand voice doc you upload once. Uses your configured LLM (Claude, MiniMax, or any OpenRouter model).
Summary extracts key points. Useful for verifying the article says what you intended it to say.
Safety — will this cause problems?
Legal risk scans for health claims, defamation risk, GDPR violations, false promises, and FDA violations. The kind of checks that would have caught the supplement client's exposure before it went live.
Plagiarism via Copyscape or Originality.ai. Detects copied passages.
AI detection via the same providers. Flags AI-generated content where disclosure matters.
Content design — does it fit the brief?
Brief matching checks the article against a project brief you provide. Verifies it covers the required points.
Purpose verifies the article is doing what it's supposed to do — awareness piece, conversion page, explainer — and flags drift.
Academic citations (Semantic Scholar enricher) — merges real citation data onto medical and scientific claims. Free.
Every skill returns a structured verdict: pass, warn, fail, or skipped (when a skill isn't configured — not an error, just not running). The report shows skill-by-skill findings with evidence, not just a score.
Provider choice happens per skill from the dashboard. Settings → Providers. You pick Exa Search, Exa Deep Reasoning, or Parallel Task for fact-check, LanguageTool or Sapling for grammar, Cloudflare or Pinecone for self-plagiarism, Claude or MiniMax for LLM skills. You can estimate your cost before running:
checkapp --estimate-cost article.md
The MCP server returns structured SkillResult[] JSON with sources, citations, rewrites, claim types, and per-claim confidence scores. If your agent drafts the article, it can check the article too — one tool call, structured response, no scraping.
What it is not
CheckApp is not a content generator. It does not write articles. It checks them.
It's not an editor replacement. It finds problems and returns evidence. You decide what to fix.
It's not free to run. It's free software (MIT) but BYOK means you pay your API providers directly. With free-tier providers (LanguageTool for grammar, Semantic Scholar for academic citations, offline SEO, Upstash Vector for self-plagiarism) plus a cheap fact-check provider like Exa Search (~$0.007/claim), the cost approaches a few cents per article. With Exa Deep Reasoning for fact-check and Copyscape for plagiarism, it's closer to $0.25. You control the spend.
It's not tuned for every language. English and Hebrew are tested and calibrated. Other scripts (CJK, Arabic, Russian) are detected but the SEO scoring, sentence splitting, and passage matching are not optimized. That's Phase 8.
It's not perfect. False positives happen. A claim that's true but poorly worded may come back as warn. You're the last reviewer. CheckApp is the gate before you.
Why open source and BYOK
Most AI SaaS tools resell API tokens at 3–10× cost. You pay $29/month for $3 of API calls. That's a normal business model. It's also an opaque markup on infrastructure you could own yourself.
CheckApp's markup is zero.
Your API calls go directly from your machine to your configured providers. CheckApp never sees your tokens, never proxies your text, never sits between you and the provider. If you trust Anthropic's data policy, CheckApp doesn't add a second layer. If you use a self-hosted LanguageTool instance, your text never leaves your network.
The code is MIT. Fork it, modify it, deploy it for your team. The skills system is modular — you can add providers or build new skills against the same interface.
Install it today
It's v1.2.0. It's shipped. Run your next article through it before you publish.
npm install -g checkapp
checkapp --setup
checkapp article.md
The fastest path is checkapp --ui — opens the dashboard at localhost:3000 with provider settings, per-skill configuration, cost estimates before running, history, and HTML/JSON export. If you prefer the terminal, --setup walks you through provider configuration. Pick the free-tier providers to start — LanguageTool for grammar, Semantic Scholar for academic citations — and run your first check for pennies.
For Claude Code: install the MCP server from the GitHub repo and check_article becomes a native tool in your agent workflow. Your agent drafts. Then it checks.
If you write things where being wrong matters, install it. Open an issue if something breaks. That's how it gets better.
Was this useful?
Share it with someone who ships AI content.
Continue reading
I Ran 5 Client Articles Through CheckApp — Here's What It Caught
Five real client articles — fintech, wellness, SaaS, B2B, onboarding. A contradicted statistic, FDA-risk phrases, a plagiarism near-miss, and self-plagiarism the writer didn't know about.
CheckApp vs Grammarly vs ChatGPT vs Copyscape
An honest comparison of four content quality tools across grammar, plagiarism, fact-checking, AI detection, tone matching, and legal risk — for agencies, marketers, and writers.
Try CheckApp
Open source. MIT. ~$0.15/check (estimate). Install in 60 seconds.